간단하게 드래그 앤 드롭 만으로 pdf 이미지 텍스트 추출 사이트를 이용해서 글자 인식을 시키는 방법에 대해 소개해 드립니다.
이렇게 사진이나 이미지 파일 등에 있는 글자를 인식하는 기술을 광학 문자 인식(OCR; Optical Character Recognition)이라고 합니다.
이미지나 사진에서 글자를 추출해 내는 방법은 여러 가지가 있습니다.
그러나 여기에서는 img2txt 라는 웹사이트를 통해 정말 간단하게 변환하는 방법에 대해 설명드리도록 하겠습니다.
해당 사이트 이용시 주의할 사항도 하단에 적어 놓았으니 참고하시기 바랍니다.
이미지에서 텍스트 추출 하기
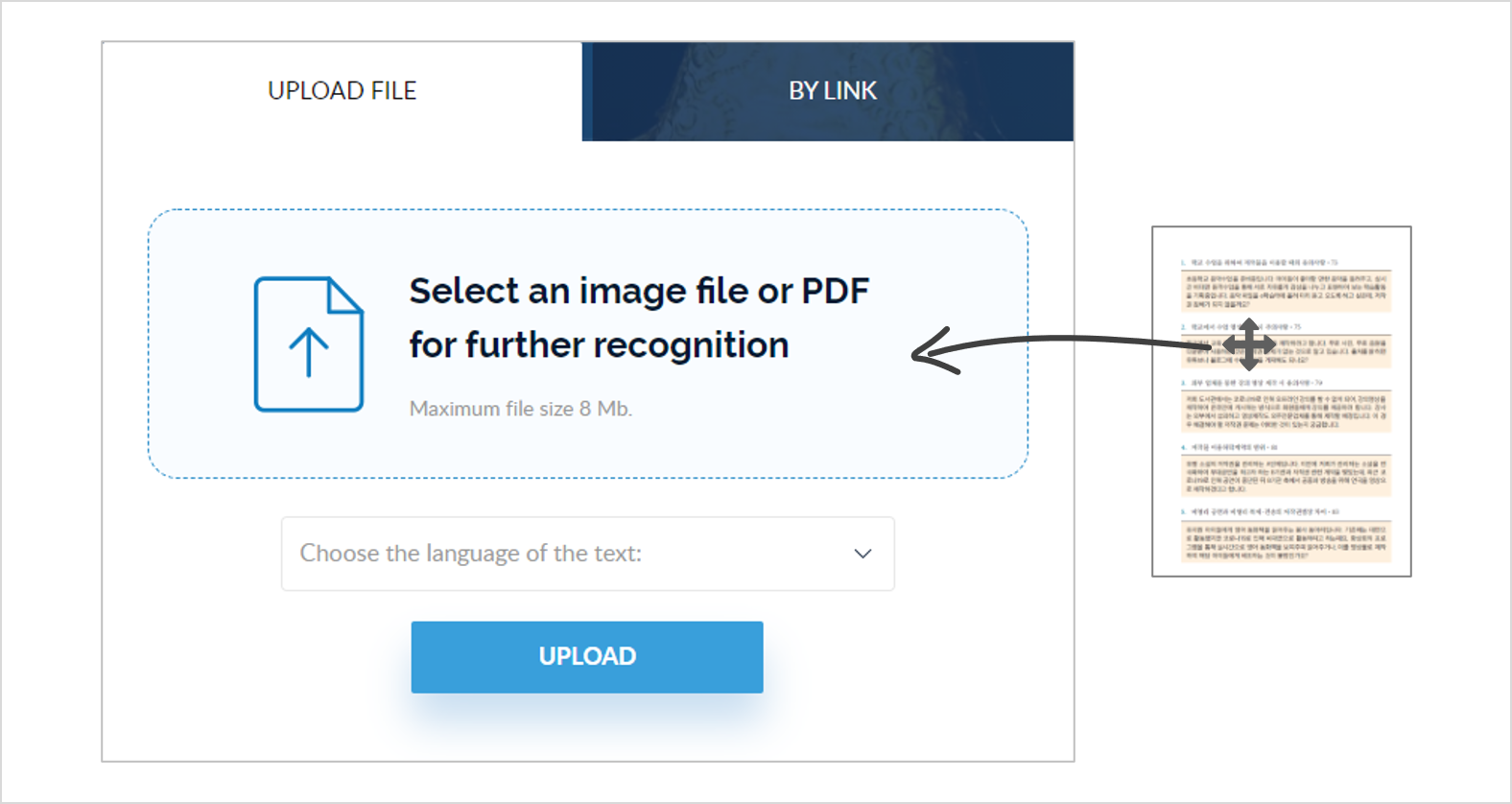
먼저 종이문서를 스캔하거나 사진을 찍거나 해서 디지털 파일로 되어 있는 문서를 이용해 이미지에서 텍스트 추출 하기를 해 보겠습니다.
사용 방법은 매우 간단합니다.
jpg나 png 등으로 되어 있는 이미지 파일을 Drag & Drop 해서 박스 안에 넣기만 하면 됩니다.
업로드할 수 있는 파일의 최대 용량은 8Mb입니다.
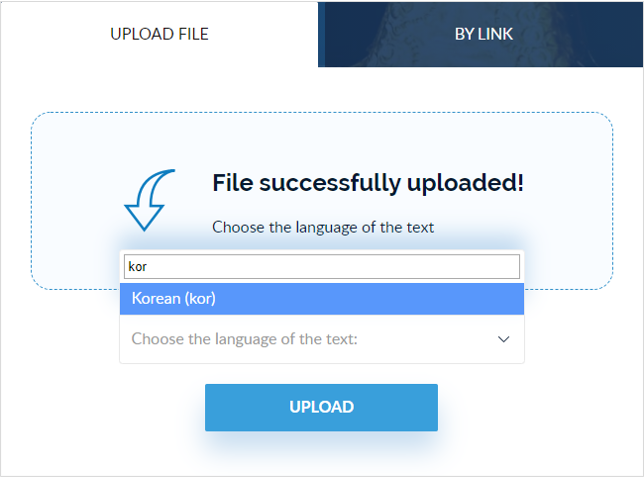
파일 업로드가 완료되었다는 메시지가 나오면 하단에 있는 'Choose the language of the text' 셀렉트 박스를 눌러서 언어를 설정합니다.
한글 파일의 경우 'Korean(kor)'을 선택해 주세요.
언어 선택 리스트가 많기 때문에 찾기 힘들면 입력란에 'kor'라고 입력하면 쉽게 찾을 수 있습니다.
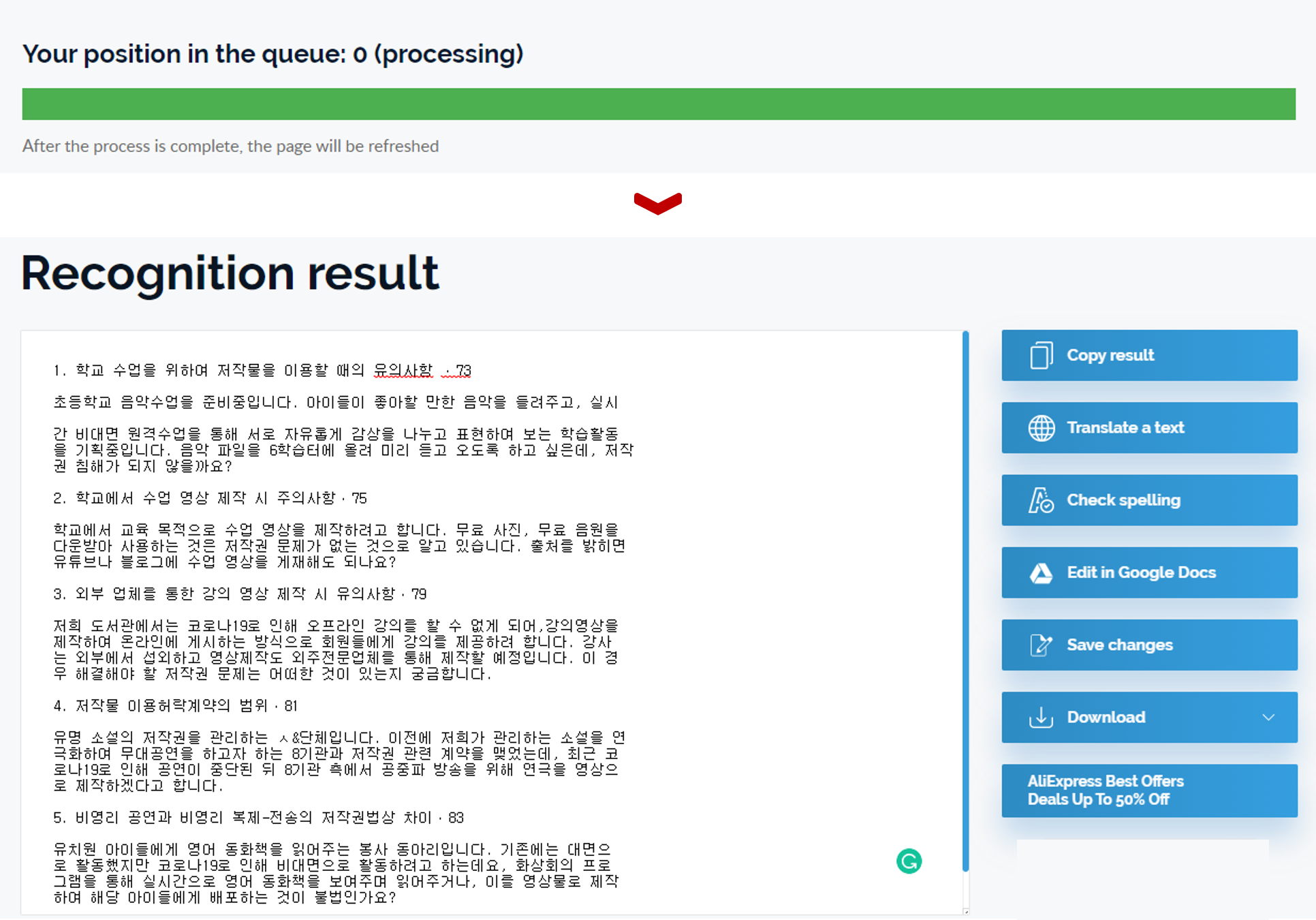
업로드를 하면 위와 같이 progress bar가 나오는데요.
업로드 완료 후에 약 3~4초 정도 기다리시면 이미지에서 텍스트 추출이 되어 결과가 나타납니다.
결과값이 나온 페이지를 보면 비교적 괜찮게 인식된 것을 확인할 수 있습니다.
OCR 기능을 사용할 때는 최대한 원본 이미지가 선명해야 좋은 결과가 나타나는데요.
영어의 경우 인식률이 거의 100%에 가까울 정도로 정확하게 인식하는 반면 한글은 약 90% 정도 수준의 인식률을 보이더라고요.
이건 img2txt 만의 문제가 아니라 대부분의 OCR 프로그램이나 사이트는 비슷한 것 같아요.
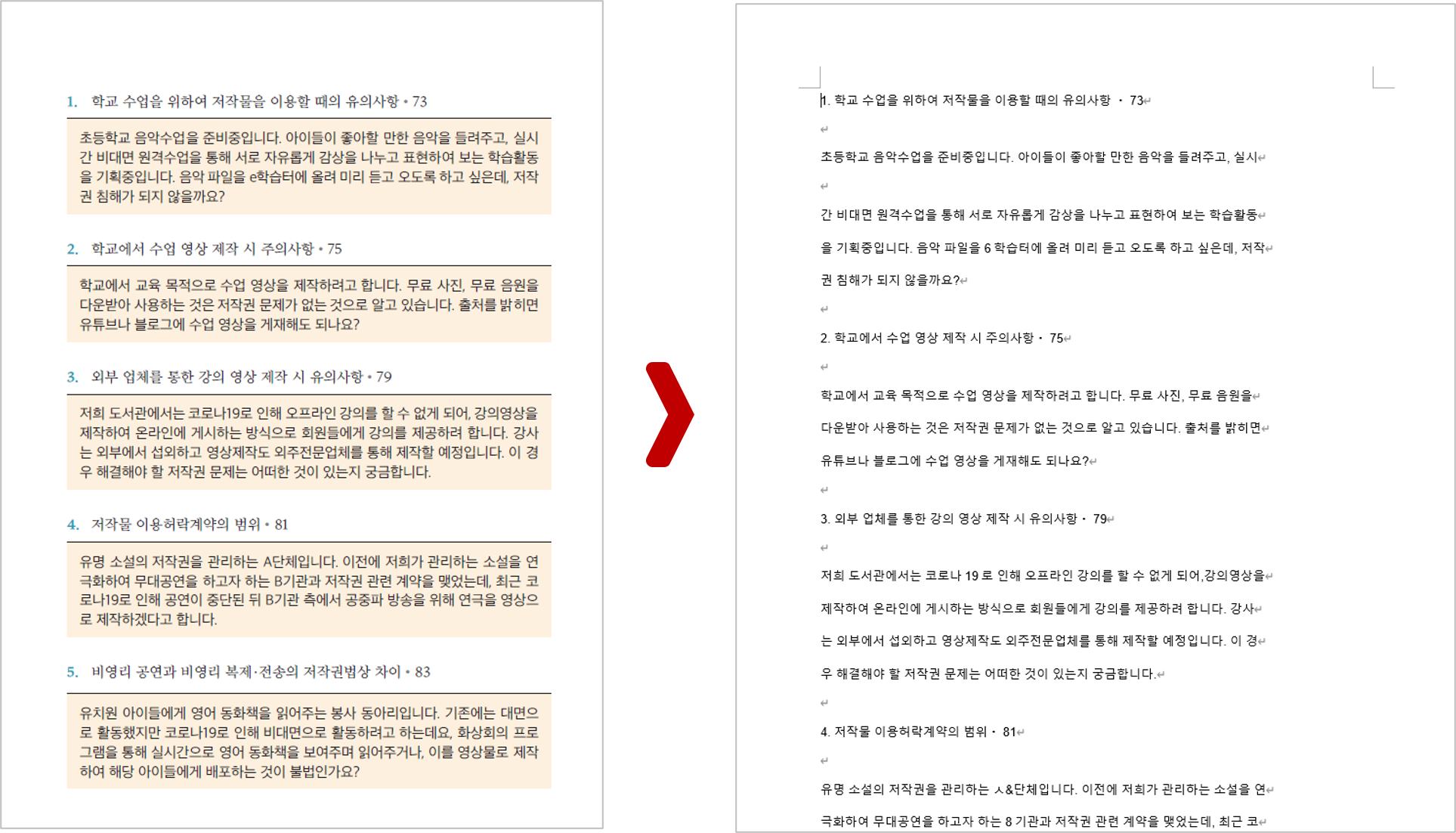
다운로드 옵션을 통해서 워드(MS Word) 파일로 바꿔서 저장해 보았는데요.
기본적으로 플레인 텍스트 형태로 나오다 보니 본문의 편집 스타일은 사라진다고 보시면 됩니다.
어차피 한글 OCR 인식률이 약간 떨어져서 후가공 작업이 필요하니 텍스트로 나오는 게 좋은 것 같습니다.
pdf에서 텍스트 추출 하기
pdf를 이용해 텍스트 추출하는 것도 이미지에서 하는 것과 방법은 동일합니다.
드래그 앤 드롭으로 인식하고자 하는 파일을 넣어주세요.

위와 같이 pdf에서 텍스트 추출을 완료해 보았습니다.
pdf를 전환하면 별도로 다운르도 받거나 할 수는 없고, 인식되는 텍스트를 복사해서 다른 워드 같은 프로그램에 붙여 넣어야 합니다.
※ pdf 이미지 텍스트 추출 시 알아 두어야 할 점(주의점)
* 문서는 단일 언어로 되어 있는 파일이어야 합니다.
- 한글과 영어가 섞여 있는 문서에서 '한글'을 선택해서 뽑아내면 영어는 숫자 같은 것으로 인식이 됩니다. 후보정 필요합니다.
* pdf 문서는 이미지를 pdf로 변환한 파일이 아닌 텍스트를 긁을 수 있는 파일을 사용해야 합니다.
- pdf 보안이 걸려 있어서 일반적인 방법으로 텍스트 복사가 되지 않는 상태일 때 img2txt에 넣으면 글자를 인식할 수 있는 상태로 추출할 수 있습니다.
'Application > PC' 카테고리의 다른 글
| 동영상 음성 추출 하는 방법(mp4 to mp3) (1) | 2022.01.30 |
|---|---|
| pdf 회전 저장이 가능한 Smallpdf 무료 프로그램 (0) | 2021.12.03 |
| OBS 설정 후 디스플레이캡쳐 검은화면 나올때 해결방법 (1) | 2020.12.08 |
| 곰플레이어 코덱 설치하는 방법(통합코덱) (0) | 2020.09.11 |
| 윈도우 사용자 휴대폰 앱 삭제하는 방법 (5) | 2020.09.09 |